Mikä on Web Scraping ja miten se toimii digitaalisessa maailmassa
Data ja tiedot ovat kaksi termiä, joita käytetään usein vaihtokelpoisesti, mutta niiden välillä on huomattava ero. Esimerkiksi data viittaa tiedon bitteihin, mutta ei itse tietoon. Toisaalta tieto(Information) on joukko tietoja, joita käsitellään mielekkäällä tavalla. Internetistä saatavilla olevan valtavan datan ansiosta erilaisia lähestymistapoja, kuten Web Scraping , Web Harvesting tai Web Data Extraction , käytetään luomaan toimivia ja peliä muuttavia oivalluksia Internetin(Internet) käytöstä. Mutta mitä ne tarkalleen ottaen tarkoittavat verkkomaailmassa. Katsotaanpa!
Miten Web Scraping toimii
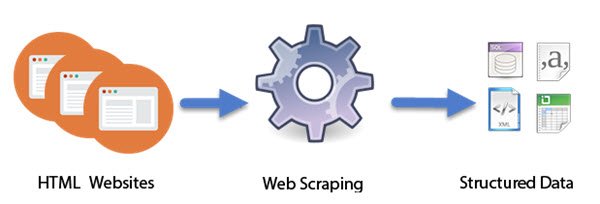
Älykkäiksi (Computer)boteiksi(Intelligent) suunnitellut tietokoneohjelmat tekevät Web Scraping - työn . Toisin kuin näytön kaapiminen, joka kopioi vain näytöllä näkyvät pikselit, verkkokaappaus poimii taustalla olevan HTML - koodin ja sen mukana tietokantaan tallennetut tiedot. Lähestymistavasta on tullut varsin suosittu. Itse asiassa sitä pidetään yhtenä olennaisista taidoista, jotka on hankittava nykypäivän digitaalisessa maailmassa. Sillä on hienoja sovelluksia suurten tietojoukkojen kokoamisessa, jotka ovat olennaisia tekniikoille, kuten
- Big Data Analytics
- Koneoppiminen
- Tekoäly(Artificial Intelligence)
Digitaalisen tiedon nopean laajentumisen myötä Big Datan käyttäminen (Big Data)Web Scraping- tai Web Data Extraction -lähestymistavan avulla on tullut paljon helpommaksi. Web Scrapingia(Web Scraping) voidaan kuitenkin käyttää digitaalisissa yrityksissä, jotka luottavat tiedonkeruuun sekä laillisissa(Legitimate) että laittomissa tapauksissa. Edellinen sisältää Benevolent Web(Benevolent Web Scraping Examples) Scraping -esimerkkejä , kun taas jälkimmäinen sisältää esimerkkejä haittaohjelmien Web(Malicious Web Scraping) -kaappauksesta .
Esimerkkejä hyväntekeväisestä verkkokaappauksesta
- Hakukonebotit(Search) indeksoivat sivustoa ja analysoivat sen sisältöä määrittääkseen sijoituksen tiettyjen havaintojen, kuten Googlen(Google) , perusteella .
- Hintavertailusivustot(Price) , jotka ottavat käyttöön botteja tuotteiden hintojen automaattiseen noutamiseen
- Markkinatutkimusyritykset(Market) , jotka käyttävät kaavinta tiedon poimimiseen sosiaalisesta mediasta (esim. tunteiden analysointiin, henkilökohtaisiin mieltymyksiin jne.).
Esimerkkejä haitallisesta Web-kaappauksesta
Verkkojen kaapiminen(Web Scraping) laittomiin tarkoituksiin voi aiheuttaa vakavia taloudellisia menetyksiä, jos tietoja poimitaan ilman verkkosivuston omistajien lupaa. Haitallisen Web(Malicious Web Scraping) -kaappauksen kaksi yleisintä käyttötapausta ovat hinnan kaapiminen ja sisällön varkaus.
- Price Scraping – Scraper -botit tarkastavat kilpailevia yritystietokantoja saadakseen pääsyn hinnoittelutietoihin, alittaakseen kilpailijansa ja lisätäkseen myyntiä.
- Sisällön varkaus(Content Theft) – Tämä laiton toiminta käsittää laajamittaisen sisällön varkauden kohdesivustolta. Tyypillisiä kohteita ovat pääasiassa online-tuoteluettelot ja verkkosivustot, jotka tukeutuvat digitaaliseen sisältöön liiketoiminnan edistämiseksi.
Toivottavasti tämä auttaa!

About the author
Olen tietojenkäsittelytieteilijä, joka keskittyy yksityisyyteen ja käyttäjätileihin sekä perheen turvallisuuteen. Olen työskennellyt älypuhelinten tietoturvan parantamisessa viime vuosina, ja minulla on kokemusta työskentelystä peliyritysten kanssa. Olen myös kirjoittanut useaan otteeseen käyttäjätileihin ja pelaamiseen liittyvistä ongelmista.
Related posts
Ei Internet-yhteyttä, mutta näkyy muodossa Yhdistetty Internetiin
Mikä on Bitcoin, digitaalinen valuutta
Mitä tapahtuu online-tileillesi, kun kuolet: digitaalisen omaisuuden hallinta
Mikä on Dark Web tai Deep Web? Pääsy ja varotoimet.
Digital Detox -hoidon edut ja miten edetä siinä
Asenna Internet Radio Station ilmaiseksi Windows PC:lle
Reitittimen IP-osoitteen löytäminen Windows 10:ssä - IP-osoitteen haku
Internet ei toimi Windows 11/10 -päivityksen jälkeen
Internet- ja sosiaalisten verkostoitumissivustojen riippuvuus
DDoS:n hajautetut palvelunestohyökkäykset: suojaus, ehkäisy
Tietoverkkorikollisuus ja sen luokittelu - Järjestäytynyt ja järjestämätön
Estettyjen tai rajoitettujen verkkosivustojen eston poistaminen ja pääsy niihin
Akun virran säästäminen Internet Explorerissa selatessasi Internetiä
Webin selaaminen Internet Explorer 11 -sovelluksella Windows 8.1:ssä
Internet Security -artikkeli ja vinkkejä Windows-käyttäjille
Edge- ja Store-sovellukset eivät muodosta yhteyttä Internetiin - Virhe 80072EFD
Luettelo parhaista ilmaisista Internet-tietosuojaohjelmistoista ja -tuotteista Windows 11/10:lle
Mikä on 403 Forbidden Error ja kuinka korjaan sen?
Wi-Fi vs Ethernet: Kumpaa sinun pitäisi käyttää?
Korjaa Web-sivun palautusvirhe Internet Explorerissa